graph LR init --> predict --> loss --> gradient --> step --> stop step --> repeat --> predict
训练你的第一个神经网络
神经网络训练流程
下图是训练神经网络基本的七个步骤:
- 初始化权重参数,一般采用随机化权重也会有良好的效果;
- 通过神经网络的计算,得到预测值;
- 计算损失函数,损失函数是衡量预测值与真实值之间差异的函数,损失函数越小,预测值与真实值越接近;
- 计算梯度,采用SGD(随机梯度下降)算法计算梯度,梯度是损失函数对权重参数的偏导数,表示损失函数在权重参数处的变化率;
- 更新权重参数,根据梯度更新权重参数,使得损失函数最小化;
- 重复步骤2-5,直到损失函数收敛;
- 停止神经网络训练,一般取决于两种情况:
- 达到预设的训练次数;
- 损失函数收敛到预设的阈值。
MNIST数据集
MNIST数据集是手写数字(0-9)的图片数据集,包含60000个训练样本和10000个测试样本。每个样本是一个28x28的灰度图像,表示一个手写数字。
加载MNIST数据集
# fastai课程预设置导入包
import fastbook
fastbook.setup_book()
from fastai.vision.all import *path = untar_data(URLs.MNIST)查看MNIST数据集目录结构
path.ls()[Path('D:/User/ChenBo/.fastai/data/mnist_png/testing'), Path('D:/User/ChenBo/.fastai/data/mnist_png/training')]training_path = path/'training'
training_path.ls()[Path('D:/User/ChenBo/.fastai/data/mnist_png/training/0'), Path('D:/User/ChenBo/.fastai/data/mnist_png/training/1'), Path('D:/User/ChenBo/.fastai/data/mnist_png/training/2'), Path('D:/User/ChenBo/.fastai/data/mnist_png/training/3'), Path('D:/User/ChenBo/.fastai/data/mnist_png/training/4'), Path('D:/User/ChenBo/.fastai/data/mnist_png/training/5'), Path('D:/User/ChenBo/.fastai/data/mnist_png/training/6'), Path('D:/User/ChenBo/.fastai/data/mnist_png/training/7'), Path('D:/User/ChenBo/.fastai/data/mnist_png/training/8'), Path('D:/User/ChenBo/.fastai/data/mnist_png/training/9')]testing_path = path/'testing'
testing_path.ls()[Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/0'), Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/1'), Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/2'), Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/3'), Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/4'), Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/5'), Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/6'), Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/7'), Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/8'), Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/9')]数据集中的每一张图片都是类似下图所示的一张手写阿拉伯数字
zero_path = training_path/'0'
img_0 = Image.open(zero_path.ls()[0])
img_0
开始训练
构建神经网络输入
计算机并不认识图片,需要将图片转换为数字,才能进行训练。
每张图片由28 * 28的像素点组成,每个像素点由0-255的灰度值表示,0表示白色,255表示黑色。(现代的彩色图片是基于RGB三个通道确定一个像素点)
神经网络需要基于矩阵乘法进行大量并行计算,因此我们需要将[28 * 28]像素点压缩到一个维度上,构成一个784维的向量(一阶张量)。
最终60000张训练集图片构成[60000, 784]的矩阵(二阶张量)
创建基座模型
为了使后续的模型训练有参照,每一个神经网络训练之前都应该定义一个可以快速实现的基座模型。
一个简单明了的思路是像素相似度。基于训练集图像计算出每个数字(0-9)的所有图像的像素平均值,分类时计算模型和验证集的MAE(也称作L1范式)值,分类为差值最小的数字
由于该简单模型确定为像素平均值,因此不需要进行训练,步骤简化为:
graph LR predict --> loss --> stop
# 将训练集0-9的Path加载到一个list中
training_paths = [training_path/f'{i}' for i in range(10)]
training_paths[Path('D:/User/ChenBo/.fastai/data/mnist_png/training/0'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/training/1'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/training/2'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/training/3'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/training/4'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/training/5'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/training/6'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/training/7'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/training/8'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/training/9')]# 将训练集所有图像转换为tensor,构建为一个包含60000个tensor的list,每个tensor为[28, 28]的二阶张量
training_nums = [[tensor(Image.open(image)) for image in path.ls()] for path in training_paths]
len(training_nums)10❓ 为什么一个Image对象可以通过tensor构造函数转换为tensor
核心在于
Array Interface(数组接口)协议: 协议对接: PIL的Image类实现了__array_interface__属性,主动向外暴露内存指针和形状; 底层识别:torch.tensor的构造逻辑会自动检测此属性,实现类似NumPy的无缝数据拷贝。
# 计算每个数字的像素平均值
# 1. 堆叠张量
# 2. 转成float类型
# 3. 基于维度0(即我们堆叠图片的方向)取平均值
# 4. 归一化像素值(/255,使像素值分布在[0, 1]区间)
means = [torch.stack(number).float().mean(0)/255 for number in training_nums]# 查看0-9在MNIST训练集平均像素下的图像
show_images(means)
#加载测试集
testing_paths = [testing_path/f'{i}' for i in range(10)]
testing_paths[Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/0'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/1'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/2'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/3'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/4'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/5'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/6'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/7'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/8'),
Path('D:/User/ChenBo/.fastai/data/mnist_png/testing/9')]# 堆叠10个数字平均像素图像
mean_stack = torch.stack(means)
mean_stack.shapetorch.Size([10, 28, 28])# 定义基座模型的损失函数(像素相似度)
# preds: 形状为 [10, 28, 28] 的预测张量(0-9的平均像素图)
# targets: 测试集图像张量
# 步骤:
# 1. targets.unsqueeze(1): 扩展维度以便广播,形状变为 [N, 1, 28, 28]
# 2. (preds - ...).abs(): 计算每张测试图与10个平均图的绝对差值(MAE/L1范式)
# 3. .mean((-1, -2)): 对28x28像素维度取平均,得到每张图与每个数字的相似度分数
# 4. .argmin(1): 取差值最小的数字索引,即预测结果
def mean_loss(preds, targets):
return (preds - targets.unsqueeze(1)).abs().mean((-1, -2)).argmin(1)# 加载测试集
testing_nums = [[tensor(Image.open(image)) for image in path.ls()] for path in testing_paths]
len(testing_nums)10# 计算验证集的准确度
similarity_accuracy = []
for i,test_num in enumerate(testing_nums):
curr = (mean_loss(mean_stack, torch.stack(test_num)) == i).float().mean()
similarity_accuracy.append(curr)
print(f"accuracy of {i}: ", curr.item())accuracy of 0: 0.9132652878761292
accuracy of 1: 0.9964757561683655
accuracy of 2: 0.5145348906517029
accuracy of 3: 0.7405940890312195
accuracy of 4: 0.6537678241729736
accuracy of 5: 0.22757847607135773
accuracy of 6: 0.8486430048942566
accuracy of 7: 0.7821011543273926
accuracy of 8: 0.6529774069786072
accuracy of 9: 0.8334985375404358# 平均准确率
torch.stack(similarity_accuracy).mean().item()0.7163436412811279可见这么简单的一个模型(不需要训练),仅通过像素平均值,准确率就达到了71.63%,作为我们的基座模型,是一个很好的起点。
但是其余接近30%判断错误的图像究竟是长什么样呢,以至于容易混淆?让我们一探究竟
# 查看testing数据集中0的图像
mean_loss(mean_stack, torch.stack(testing_nums[0]))tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 0, 0, 3, 0, 6, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 8, 0, 0, 0, 0, 0, 0, 0, 0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 9, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 9, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 9, 6, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 0, 6, 0, 0, 0, 0, 6, 0, 0, 0, 6, 0, 0, 0, 6, 0, 0, 0, 0, 5, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 8, 0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 9, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8, 0, 0, 0, 0, 0,
0, 9, 0, 0, 0, 8, 0, 0, 0, 6, 0, 0, 0, 8, 0, 0, 0, 0, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 0, 6, 0, 0, 0, 0, 0, 9, 0, 0, 0, 0, 0, 0, 6, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 0, 0, 3, 0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 6, 9, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8, 0, 0, 6, 9, 8, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 7, 0, 1, 0, 0, 4, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, 0, 0, 8, 0, 0, 0, 0,
6, 0, 6, 0, 0, 0, 0, 0, 0, 0, 6, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 8, 0, 6, 0, 0, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 0, 0, 0,
0, 0, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 6, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])可以看到第10张图片(索引下标为9)被误判成了6,让我们加载下这张图片看看
testing_zero = testing_paths[0].ls()
img_0_9 = Image.open(testing_zero[9])
img_0_9
这个0确实长的有点犯规,有那么一丢丢像6
再看下第13张(索引下标为12)长得像3的图片
img_0_12 = Image.open(testing_zero[12])
img_0_12
这个0就和3没什么关联性了,可见基于像素平均值是一个很粗糙的模型构建法。
下面让我们正式进入神经网络训练,看看神经网络的魔力吧!
神经网络训练
加载数据集DataLoaders
fastai中的数据集由一个(训练集,验证集)通过DataLoaders构造函数,即dls = DataLoaders(train_dl, test_dl)创建 dl由DataSet拆分成mini-batch产生 DataSet是由(模型输入x, 对应的标签y)元组组成的列表
# 构造模型输入x,即由所有训练集图像的一维向量(tensor)构成的list
training_tensors = [tensor(Image.open(image)) for path in training_paths for image in path.ls()]
training_stack = torch.stack(training_tensors).float() / 255
train_x = training_stack.view(-1, 28 * 28)
train_x.shapetorch.Size([60000, 784])# 构造模型输入对应的标签y
# 构建标签y有两种方案,与神经网络的建模相对应。
# 1. 使用one-hot编码,将标签y编码成shape=[10]的一阶张量(向量),神经网络输出要做softmax归一化处理。
# 2. 直接编码0-9对应的数字,神经网络输出保持Logits,不需要做softmax,损失函数使用交叉熵。
# 这里我们采用方案二
train_y = []
for i, path in enumerate(training_paths):
train_y.extend([i] * len(path.ls()))
train_y = tensor(train_y)
train_y.shapetorch.Size([60000])# 构造训练集dataloder
train_ds = list(zip(train_x, train_y))
train_dl = DataLoader(train_ds, batch_size=256)# 如法炮制测试集合的dataloder
testing_tensors = [tensor(Image.open(image)) for path in testing_paths for image in path.ls()]
testing_stack = torch.stack(testing_tensors).float() / 255
test_x = testing_stack.view(-1, 28 * 28)
test_y = []
for i, path in enumerate(testing_paths):
test_y.extend([i] * len(path.ls()))
test_y = tensor(test_y)
test_ds = list(zip(test_x, test_y))
test_dl = DataLoader(test_ds, batch_size=256)dls = DataLoaders(train_dl, test_dl)初始化权重
# 使用pytorch的nn.Sequential模块定义最简单的神经网络,由两层线性层、一层ReLU激活函数组成。
# 初始维度为28 * 28=784(每一张数据集图片由28 * 28的像素点组成),输出维度为10(分别代表0-9),中间层维度为30(中间层维度可以随意设置,表示神经网络可以捕获的特征数量)。
# 模型的权重由nn.Linear()随机初始化。
simple_net = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 10)
)定义损失函数
交叉熵损失函数:直接使用CrossEntropyLossFlat()函数即可,等同于nn.CrossEntropyLoss,区别在于CrossEntropyLossFlat会展平inputs和targets
定义优化器
优化器采用随机梯度下降SGD
定义正确率指标
def batch_accuracy(preds, targets):
return (preds.argmax(1) == targets).float().mean()训练神经网络
learn = Learner(
dls = dls,
model = simple_net,
loss_func=CrossEntropyLossFlat(),
opt_func=SGD,
metrics=batch_accuracy
)
learn.remove_cbs(ProgressCallback)<fastai.learner.Learner at 0x2ce446b1fd0>learn.fit_one_cycle(40, lr_max=0.1)[0, 2.058319330215454, 2.217005491256714, 0.1054999977350235, '00:00']
[1, 1.026645541191101, 3.093644857406616, 0.10090000182390213, '00:00']
[2, 0.46824803948402405, 3.1218841075897217, 0.10790000110864639, '00:00']
[3, 0.2767549157142639, 3.022745132446289, 0.17020000517368317, '00:00']
[4, 0.2017069160938263, 3.0426149368286133, 0.22300000488758087, '00:00']
[5, 0.16536171734333038, 3.1070761680603027, 0.2531999945640564, '00:00']
[6, 0.14760544896125793, 3.160271406173706, 0.27799999713897705, '00:00']
[7, 0.13931012153625488, 3.1762616634368896, 0.29660001397132874, '00:00']
[8, 0.1304607093334198, 3.268145799636841, 0.2971000075340271, '00:00']
[9, 0.12770448625087738, 3.2473626136779785, 0.30469998717308044, '00:00']
[10, 0.13348078727722168, 2.9868013858795166, 0.34529998898506165, '00:00']
[11, 0.13116277754306793, 2.9267468452453613, 0.3483000099658966, '00:00']
[12, 0.1418938934803009, 2.7756187915802, 0.3547999858856201, '00:00']
[13, 0.14047884941101074, 2.686028242111206, 0.34880000352859497, '00:00']
[14, 0.1492592990398407, 2.566951274871826, 0.3587999939918518, '00:00']
[15, 0.14494456350803375, 2.585930824279785, 0.34380000829696655, '00:00']
[16, 0.14443561434745789, 2.3903746604919434, 0.38370001316070557, '00:00']
[17, 0.14076095819473267, 2.299257516860962, 0.40049999952316284, '00:00']
[18, 0.1459321826696396, 2.113252639770508, 0.42570000886917114, '00:00']
[19, 0.1465080976486206, 1.9186656475067139, 0.4675999879837036, '00:00']
[20, 0.1467052400112152, 1.8600183725357056, 0.4738999903202057, '00:00']
[21, 0.1455131471157074, 1.7872105836868286, 0.4810999929904938, '00:00']
[22, 0.14577575027942657, 1.637719750404358, 0.49939998984336853, '00:00']
[23, 0.14990916848182678, 1.477837085723877, 0.5246999859809875, '00:00']
[24, 0.15500810742378235, 1.3052470684051514, 0.5654000043869019, '00:00']
[25, 0.15911975502967834, 1.1460464000701904, 0.6098999977111816, '00:00']
[26, 0.1634342521429062, 1.010521411895752, 0.6489999890327454, '00:00']
[27, 0.16842171549797058, 0.9010326862335205, 0.6820999979972839, '00:00']
[28, 0.1747148036956787, 0.7957713603973389, 0.7116000056266785, '00:00']
[29, 0.1830490231513977, 0.691900908946991, 0.7461000084877014, '00:00']
[30, 0.19352246820926666, 0.5899965167045593, 0.78329998254776, '00:00']
[31, 0.2064102739095688, 0.4935455620288849, 0.8199999928474426, '00:00']
[32, 0.22154438495635986, 0.407286673784256, 0.8560000061988831, '00:00']
[33, 0.2384401112794876, 0.3356265425682068, 0.8860999941825867, '00:00']
[34, 0.2557208836078644, 0.28089436888694763, 0.9089999794960022, '00:00']
[35, 0.2705569863319397, 0.24455700814723969, 0.9248999953269958, '00:00']
[36, 0.27901846170425415, 0.2253568172454834, 0.9315999746322632, '00:00']
[37, 0.2801212668418884, 0.21798881888389587, 0.9340999722480774, '00:00']
[38, 0.27724072337150574, 0.21609164774417877, 0.934499979019165, '00:00']
[39, 0.27388298511505127, 0.21590690314769745, 0.934499979019165, '00:00']加深网络
simple_net2 = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 10)
)learn2 = Learner(
dls = dls,
model = simple_net2,
loss_func=CrossEntropyLossFlat(),
opt_func=SGD,
metrics=batch_accuracy
)
learn2.remove_cbs(ProgressCallback)<fastai.learner.Learner at 0x2ce443f2350>learn2.fit_one_cycle(40, lr_max=0.1)[0, 2.284194231033325, 2.2780888080596924, 0.10909999907016754, '00:00']
[1, 1.7273132801055908, 3.121453285217285, 0.10090000182390213, '00:00']
[2, 0.6533521413803101, 4.710193157196045, 0.10090000182390213, '00:00']
[3, 0.3517478406429291, 4.200509071350098, 0.10300000011920929, '00:00']
[4, 0.26247790455818176, 3.8570432662963867, 0.1111999973654747, '00:00']
[5, 0.22667746245861053, 3.7390215396881104, 0.13210000097751617, '00:00']
[6, 0.19849027693271637, 3.7495152950286865, 0.1736000031232834, '00:00']
[7, 0.1698937714099884, 3.976940631866455, 0.1899999976158142, '00:00']
[8, 0.16094760596752167, 3.9729621410369873, 0.24040000140666962, '00:00']
[9, 0.15071767568588257, 4.124275207519531, 0.20829999446868896, '00:00']
[10, 0.1586325764656067, 3.9294629096984863, 0.22370000183582306, '00:00']
[11, 0.1524275243282318, 3.6151387691497803, 0.27469998598098755, '00:00']
[12, 0.13830970227718353, 3.7923121452331543, 0.26330000162124634, '00:00']
[13, 0.1439690738916397, 3.4316086769104004, 0.31200000643730164, '00:00']
[14, 0.1358300894498825, 3.3017468452453613, 0.3206999897956848, '00:00']
[15, 0.1349460333585739, 3.4888715744018555, 0.3122999966144562, '00:00']
[16, 0.1303459256887436, 3.5109198093414307, 0.2890999913215637, '00:00']
[17, 0.12825831770896912, 3.3352859020233154, 0.32919999957084656, '00:00']
[18, 0.12744906544685364, 3.128218173980713, 0.3625999987125397, '00:00']
[19, 0.13217177987098694, 2.9774820804595947, 0.38350000977516174, '00:00']
[20, 0.13185277581214905, 2.9294333457946777, 0.38420000672340393, '00:00']
[21, 0.12433288991451263, 2.8967883586883545, 0.4018000066280365, '00:00']
[22, 0.1206083744764328, 2.7341668605804443, 0.4332999885082245, '00:00']
[23, 0.13059327006340027, 2.306130886077881, 0.4700999855995178, '00:00']
[24, 0.13621307909488678, 2.0357391834259033, 0.48420000076293945, '00:00']
[25, 0.13968567550182343, 1.8700580596923828, 0.5041999816894531, '00:00']
[26, 0.1441369503736496, 1.6961122751235962, 0.5260000228881836, '00:00']
[27, 0.14897668361663818, 1.5259608030319214, 0.5483999848365784, '00:00']
[28, 0.15509507060050964, 1.3486348390579224, 0.5794000029563904, '00:00']
[29, 0.16277877986431122, 1.1601871252059937, 0.6193000078201294, '00:00']
[30, 0.1735440194606781, 0.970603346824646, 0.6699000000953674, '00:00']
[31, 0.1871323585510254, 0.7937489748001099, 0.7196000218391418, '00:00']
[32, 0.2033500075340271, 0.6362507343292236, 0.7739999890327454, '00:00']
[33, 0.22262418270111084, 0.5009270310401917, 0.8213000297546387, '00:00']
[34, 0.24486522376537323, 0.38955897092819214, 0.8644000291824341, '00:00']
[35, 0.26858794689178467, 0.30733853578567505, 0.8980000019073486, '00:00']
[36, 0.28942427039146423, 0.25650855898857117, 0.9186999797821045, '00:00']
[37, 0.2997584640979767, 0.23445925116539001, 0.928600013256073, '00:00']
[38, 0.2956204414367676, 0.22947126626968384, 0.9305999875068665, '00:00']
[39, 0.2885822057723999, 0.22912432253360748, 0.9309999942779541, '00:00']可以看出,增加一层网络实际上并没有提高准确率,反而略微下降,一个原因是网络变深了但是参数量差别不大
使用RESNET18
path = untar_data(URLs.MNIST)dls = ImageDataLoaders.from_folder(path,train="training",valid="testing")learn = vision_learner(dls, resnet18, pretrained=False,
loss_func=CrossEntropyLossFlat(), metrics=accuracy)
learn.remove_cbs(ProgressCallback)<fastai.learner.Learner at 0x2ce5fe02ad0>learn.fit_one_cycle(5, 0.1)[0, 1.1184285879135132, 791.0833129882812, 0.8259999752044678, '00:32']
[1, 0.929822564125061, 3.3093323707580566, 0.9657999873161316, '00:32']
[2, 0.4890580475330353, 1.0338960886001587, 0.9674000144004822, '00:32']
[3, 0.08392318338155746, 0.047650303691625595, 0.989799976348877, '00:32']
[4, 0.026931514963507652, 0.021246496587991714, 0.9937999844551086, '00:32']正确率直接飙到99.38%,Amazing!!!
查看混淆矩阵
最后,让我们看看损失最高的图像长什么样,是否确实难以分辨
from fastai.vision.widgets import *interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()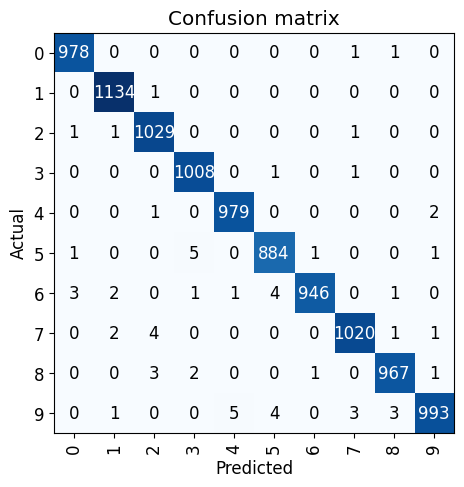
# 查看loss最高的5张图片,可以看到确实都挺难辨认的
interp.plot_top_losses(5, nrows=1)
# 以训练集中的`0`为例,这些就算是人类也难以分辨数字是0
cleaner = ImageClassifierCleaner(learn)
cleaner小结
MNIST数据集的神经网络训练作为深度学习领域的HelloWorld,想要理解并跑通并不是一件简单的事。 正如Fastai创始人Jeremy Howard所说,要想深入深度学习领域,学习者必须保持坚韧。 比如对于我来说: 2小时的课程可能对应于视频课程看3遍,jupyter notebook材料看3遍,不计其数的查询与搜索,一次次的暂停课件并卡住,才堪堪理解并完成这篇博客。
但是如你所见,最后模型的准确率是惊人的。基座模型71.63%->单层神经网络93.45%->resnet18 99.38%,而resnet18不过是一个2015年的早已过时的模型。 其中的每一步都环环相扣,然而这只是魔术,并不是魔法,一个人人都可以做到的魔术表演。